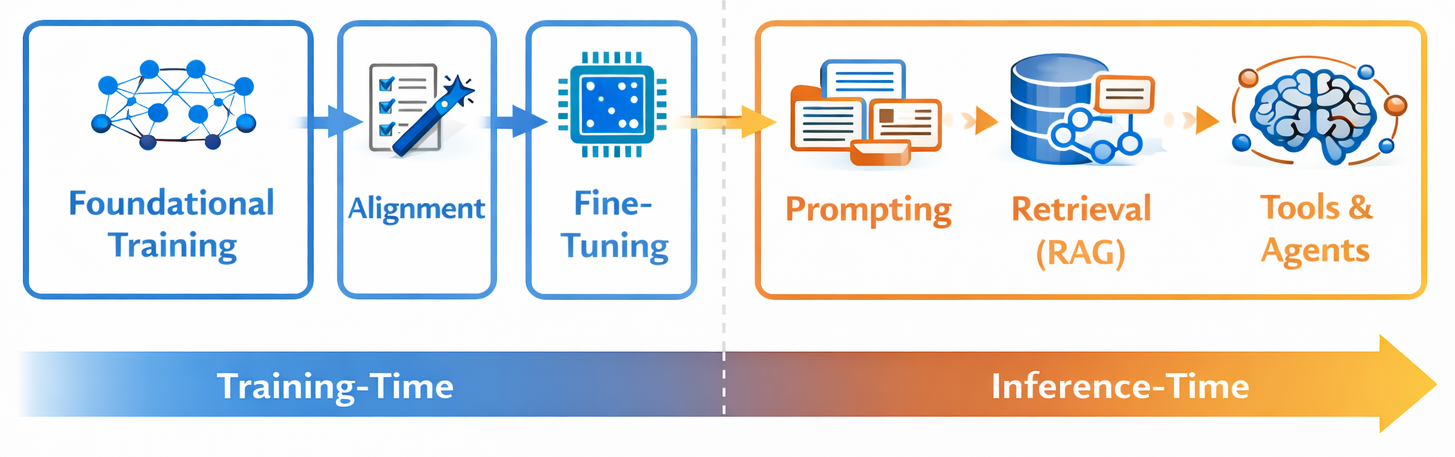
I sometimes need to explain where in the AI stack I’ve been deep-diving lately, so here’s a brief clarification.
I’ve worked across the pipeline but found a particular academic interest in the training-time stages of AI. This includes understanding model variants and internals, how they’re trained, and how we get from research to production-scale, performance-optimized systems.
Inference-Time Stages
When I talk to people about AI, a common mismatch is that they’re primarily familiar with inference-time concepts. I’ve spent time there too (RAG, MCP/tool use, agentic systems), but training time is where most capability is set. Recent advances in agentic AI are a good example: they depend on inference-time systems but are strongly enabled by training-time shaping of model behavior.
Training-Time Stages
More specifically, I’ve been focusing on resource-efficient techniques during training—especially alignment and fine-tuning. I’ve worked a lot with PEFT (Parameter-Efficient Fine-Tuning), quantization, and distillation. This focus is driven partly by intellectual interest and partly by a bias toward local AI capabilities. I’m fundamentally skeptical of a world where data and capability default to centralization, even if—at least in the short term—that’s the easiest path to rapid progress.
Robotics is another heavily training-time-focused area I’m experimenting with, though that’s still at the hobby level.
We Need More Deep Tech in Europe
Ultimately, deep tech is ingrained in my personality, and I genuinely enjoy understanding how things work.
If only there were more AI deep-tech businesses in Aarhus (and Denmark/the EU)! Of course, there’s always the option of creating one.